2/16/2024. Amazon’s Mechanical Turk (MTurk) is one of the most widely-used platforms for collecting human data for surveys and data labeling. However, there is growing concern about the declining quality of data obtained on MTurk (see
here). In response, researchers have developed a wide variety of techniques to increase data quality. One of the most common is limiting studies to participants that have completed a minimum number of tasks (HITs).
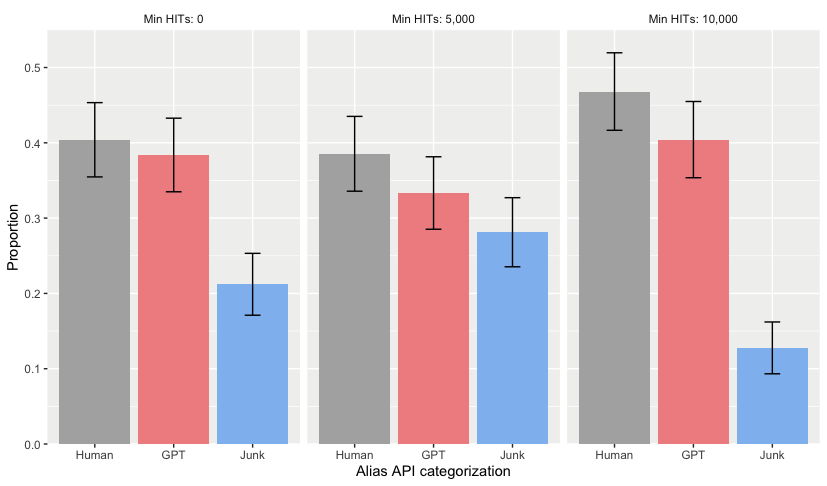
At Roundtable, we wondered the extent to which this recruitment tactic actually reduces fraud and increases data quality. We collected data from three populations, varying the required minimum number of HITs (0, 5,000, and 10,000). To measure quality, we added an open-ended question to our study (What comes to your head when you think about Boston?) and used the Roundtable Alias API to determine the proportion of responses that were Junk (unusually low-quality), GPT (superhuman and unusually long), or human.
As shown above, we found high proportions of Junk and GPT responses in all three populations. While limiting our study to participants who had completed at least 10,000 HITs led to the highest proportion of high-quality human responses, using different participant pools had a relatively negligent effect in catching fraud compared to using the Alias API. These effects may be small as they are moderated by competing processes - while newer accounts may be more likely to be fraudulent, more experienced participants may have better methods for integrating AI into their workflows.
Overall, our data suggests that rather than spend an inordinate amount of time preprocessing the participant pool to ensure data quality, researchers can be much more efficient by sampling a larger population and using the Roundtable Alias API to catch bad actors. By continually improving our models, our API lets researchers preemptively address threats to data integrity so they can focus on what they do best - conduct impactful research with high quality data.